
AI has great promise for art production, although it’s currently best suited to concept or background art rather than final assets for characters or other dynamic assets. Studios can start using AI for concept art immediately, and when used within certain constraints, AI will likely be a great tool to increase UGC.
AI still struggles with details, stylistic consistency, perspectives, and staging. Improvements to these issues are coming but not necessarily in the short term. And becaues IP and lawsuits are still a concern, it’s best to use AI as a starting point for human artists or train AI on your own content.
Use Cases
One of the most immediate applications for generative AI is concept art. Teams can use simple text-to-image prompts to quickly test out initial concepts. To create more specific images, teams can also start with reference images rather than text prompts, including photos, other pieces of concept art, or sketches. Starting with reference images allows users to explore variations on their existing concepts, such as seeing what a setting would look like in a different season, biome, time of day, or era.
Despite this obvious utility, very few game studios have publicly confirmed using AI for concept art. This could be because they are not using AI or because they are concerned about legal consequences or popular backlash. One confirmed use is from developer Lost Lore, which was able to create and refine 17 character concepts for a web3 title, Bearverse, in less than a week—something they estimate would have taken 34 business days without AI. They also used AI to generate variations on a hand-drawn building design (image, image, image). Between both asset types, they found that using AI reduced their costs by 10–15 times, which they valued at $70K in savings.



Studios are also exploring how AI can be used to create player-generated content. In February, Roblox released a demo where players could use text prompts to generate new textures on a 3D car. In March, NetEase ran an outfit creation event where players could generate concept skins with AI for their battle royale title Naraka: Bladepoint (image). The top five words that were used in the prompts will influence the design of a new skin to be released for free on the game’s anniversary.
Both of these examples succeeded by working around the limitations of current AI models, which we address in the next section. In Roblox’s case, the app used a 3D model made by human artists and applied the AI-generated textures. In NetEase’s case, Naraka: Bladepoint used the AI images as a starting point for human artists.

Other, non-gaming uses for AI image generation don’t have to be as consistent in perspective or style and so don’t need to be quite as polished to succeed. Way back in December 2021, BuzzFeed data scientist Max Woolf trained an AI model on all existing Pokémon (over 1,000). The following month, BuzzFeed published a quiz in which users answer six multiple-choice questions to generate an original “Pokémon.” The answers, which include the Pokémon’s appearance, personality, weakness, location, and two elemental types, serve as text prompts for the AI. The quality of generated creatures is mixed, but they are recognizable enough to please fans of the franchise (image).

AI has also gotten exceptionally good at modifying real-life images. TikTok hosts a range of first- and third-party AI-powered photo and video effects. Users can generate stickers and backgrounds from short text prompts. They can also turn selfies into illustrations with the AI Manga filter or create a highly realistic, retouched version of themselves with Bold Glamour, a new beauty filter released in February (image). Bold Glamour was used in over nine million videos in its first week alone, although it has attracted some criticism for promoting unrealistic beauty standards.

TikTok is also experimenting with an AI avatar generation feature in select regions. To generate avatars, users upload 3–10 portraits of themselves and select 2–5 art styles. TikTok then generates 30 avatars, which users can download, post to their story, or set as their profile avatar (image).
Similar avatar generation features will almost certainly become a part of video game character creation. In fact, NetEase’s AI research division, Fuxi Lab, developed a method to generate 3D avatars from player portraits and sketches back in 2019 (image). They detailed their process in a paper titled “Face-to-Parameter Translation for Game Character Auto-Creation”, which was co-authored with the University of Michigan, Beihang University, and Zhejiang University.

Limitations
Despite AI’s strengths, it struggles to render fine details, like hands and faces. And while Midjourney’s Version 5 update in March has greatly improved hand rendering, it still doesn’t produce consistent results.
A more widespread issue is generating assets in a style consistent with the rest of a game’s assets. Stable Diffusion allows developers to create custom image generators by training them on other visual assets from their game, increasing the AI’s output consistency. Scenario, which is built on Stable Diffusion and currently in a free beta, simplifies this process by allowing users to train their own models in a web-based UI similar to DreamStudio rather than requiring users to create a custom training program using an API (image).

Another issue is generating assets in the specific visual perspectives and staging needed for game production. ControlNet, a free third-party extension for Stable Diffusion, aims to solve this problem by providing additional conditions when training an AI model. ControlNet models can better replicate poses and positioning than vanilla Stable Diffusion by being trained on a variety of common 3D modeling and image detection criteria, including canny and HED edges, hough lines, pose detection, segmentation and depth maps, and scribble and cartoon drawings. Users can import their own staging data, such as OpenPose files exported from 3D modeling software, or let the extension pull the staging data from their uploaded images (image). But even with these tools, it will likely be some time before AI can reliably produce publishable assets.

Until technology advances, generative art will likely be restricted to background elements rather than character sprites and dynamic objects. AI-generated backgrounds can be especially effective when combined with blur or particle effects that make fine details less visible. AI-generated art can also serve as a starting point for a human artist to remix and/or work on top of.
Key Products
DALL-E is a web-based tool from Open AI, the company behind ChatGPT. It charges 13 cents per generated image, and unused credits expire one year after purchase.
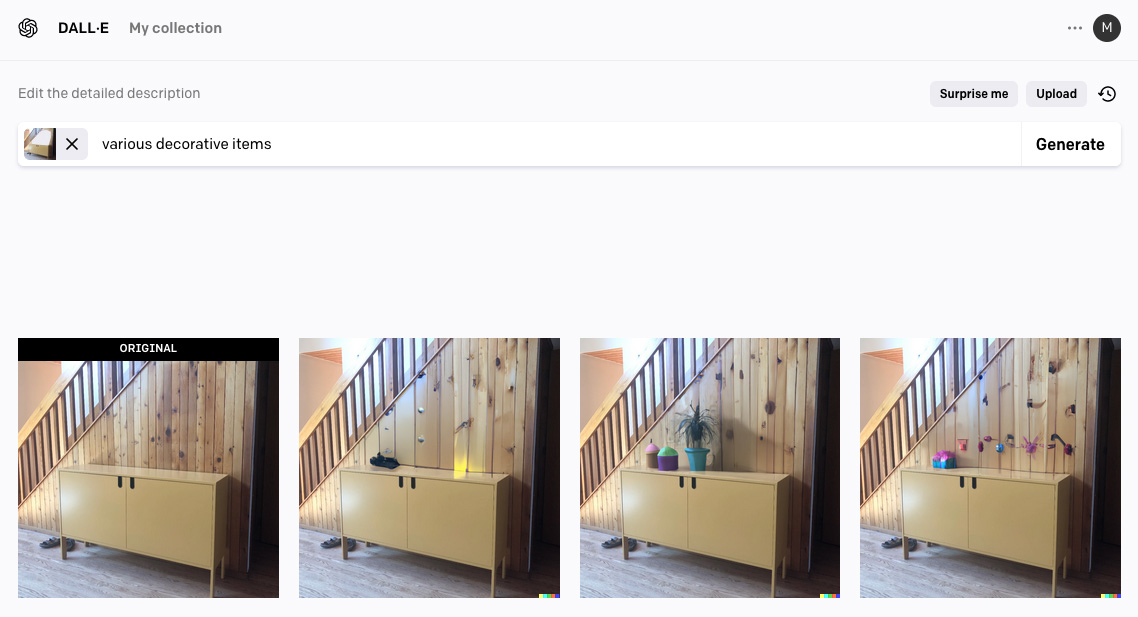
DALL-E offers a simple UI that allows users to generate and edit 1024×1024 pixel images. Users can expand their canvas’s size through outpainting, a process that generates context-aware additions off the edges of existing images. But DALL-E’s most unique feature is inpainting, which generates new content within a highlighted section of an existing image (image).
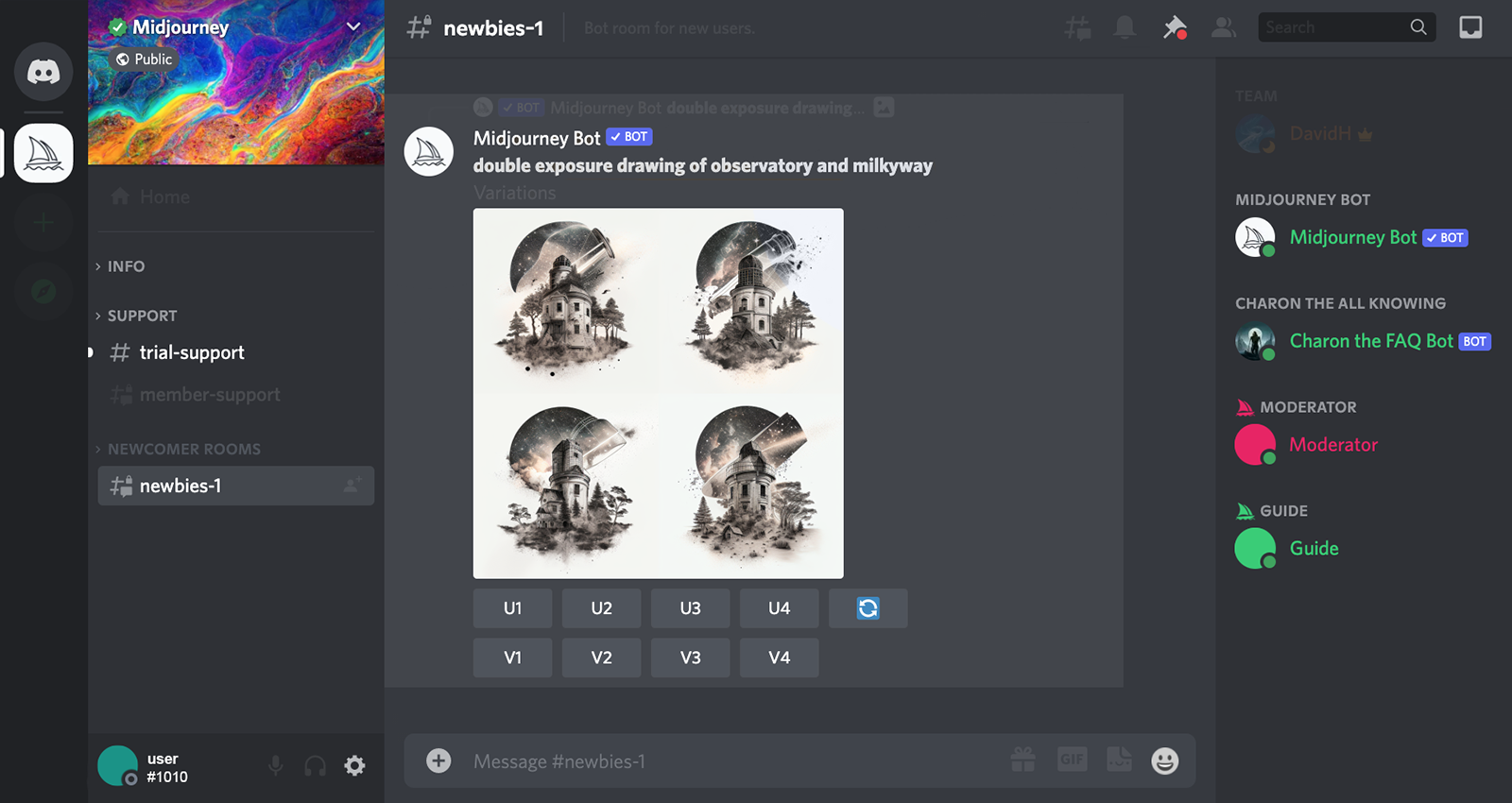
Midjourney by Midjourney Inc. is a robust Discord bot that generates images through Discord chat commands (image). It supports complex prompts, such as combinations of images and text, multiple images, and multiple strings of text. Each input can be weighted to control how much impact it has on the generated image, and negative prompts can be used to avoid unwanted criteria. Users can also specify aspect ratios, the level of detail they’re looking for, how stylized and varied they want results to be, and more.
Although Midjourney offers monthly subscriptions in three tiers ($10, $30, and $60), any company generating more than $1 million USD gross revenue per year is required to purchase the top tier. Tiers determine output speed and number of concurrent requests. All user-generated images are publicly displayed on the community showcase unless users hide them with the “stealth” feature only available to top-tier subscribers.
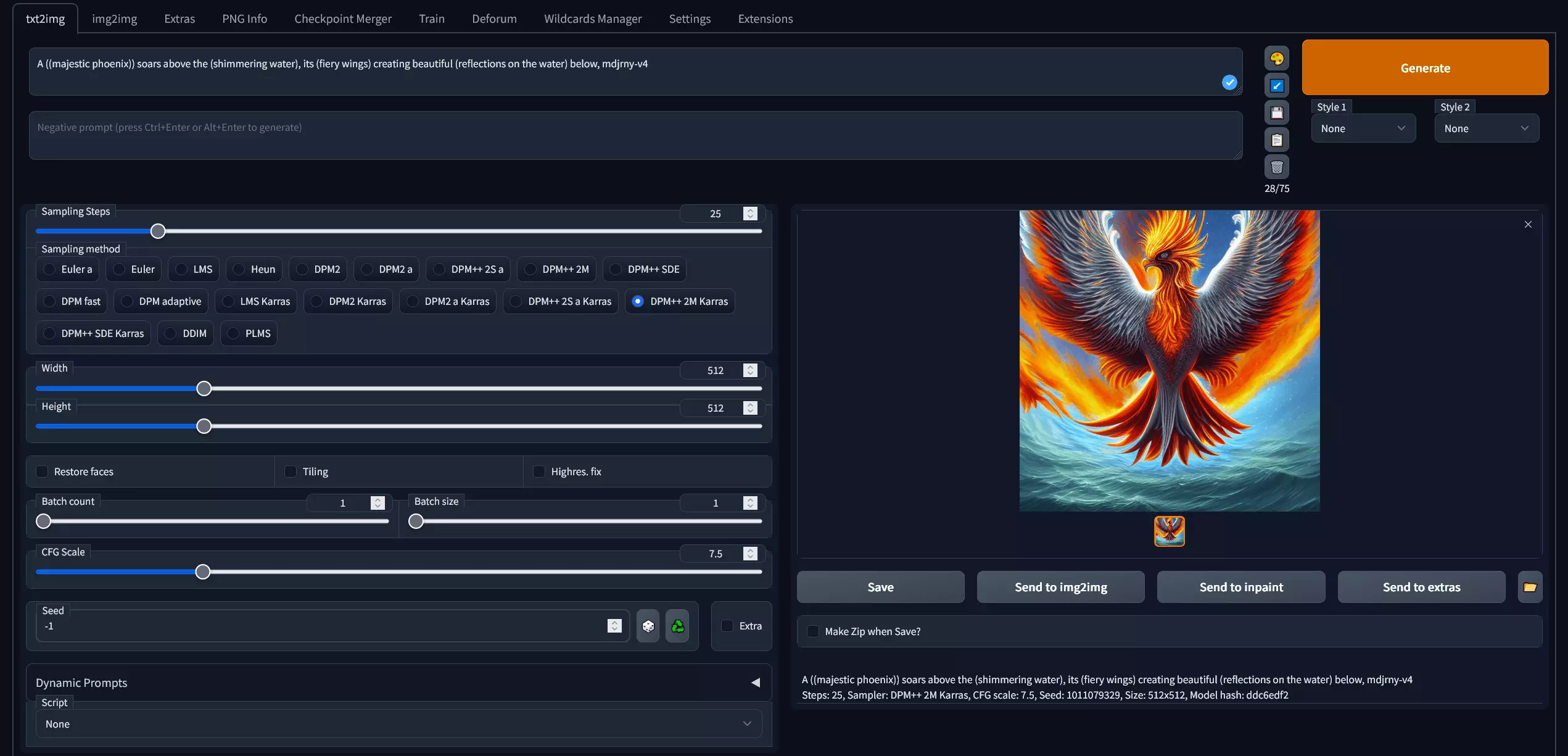
Stable Diffusion is an open-source model developed in Python by Stability AI. It is the most complicated of the three AIs in this section but also the most flexible (image). Users can customize the model to their needs and even train it on their own images through Textual Inversion, LoRA, DreamBooth, and other methods. Stability AI also has a paid web-based version called DreamStudio.
Like Midjourney, DreamStudio accepts complex prompts, including combinations of images and text, negative prompts, and various aspect ratios, but DreamStudio’s customization options aren’t as deep i (image). However, where Midjourney and DALL-E can only generate four variations at a time, DreamStudio can generate up to 10. It also offers an outpainting feature similar to the one seen in DALL-E as well as a smart eraser tool to remove unwanted content. DreamStudio costs 1 cent to 8.5 cents per generation, depending on the complexity of the request, aspect ratio, and version used.
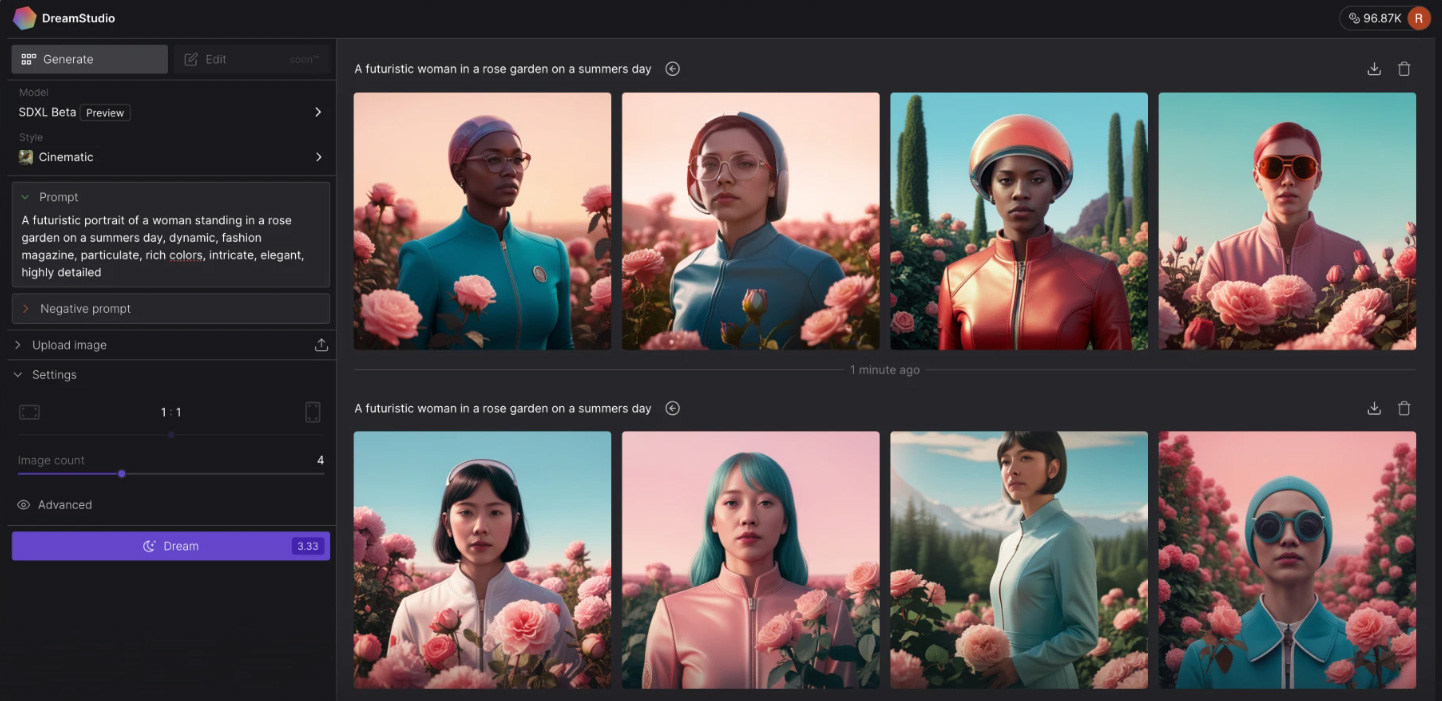
Imagen is a new cloud-based model from Google. On May 10th, Imagen migrated from Google’s AI Test Kitchen into Vertex AI, Google’s enterprise AI platform. Like Stable Diffusion, Imagen supports text and image prompts and can be fine tuned and retrained on user images. But the most impressive feature is Imagen’s mask-free editing, which allows users to iterate on images through additional text prompts (image). This is similar to DALL-E’s inpainting, but it doesn’t require highlighting. Imagen can also create text captions based on generated images and localize them on the fly.
Like other Vertex AI models, Imagen is billed by usage. Pricing ranges from $1.375–$3.465 per hour, depending on if you’re training and deploying models or generating images, with the exception of edge on-device training which costs $18 per hour.
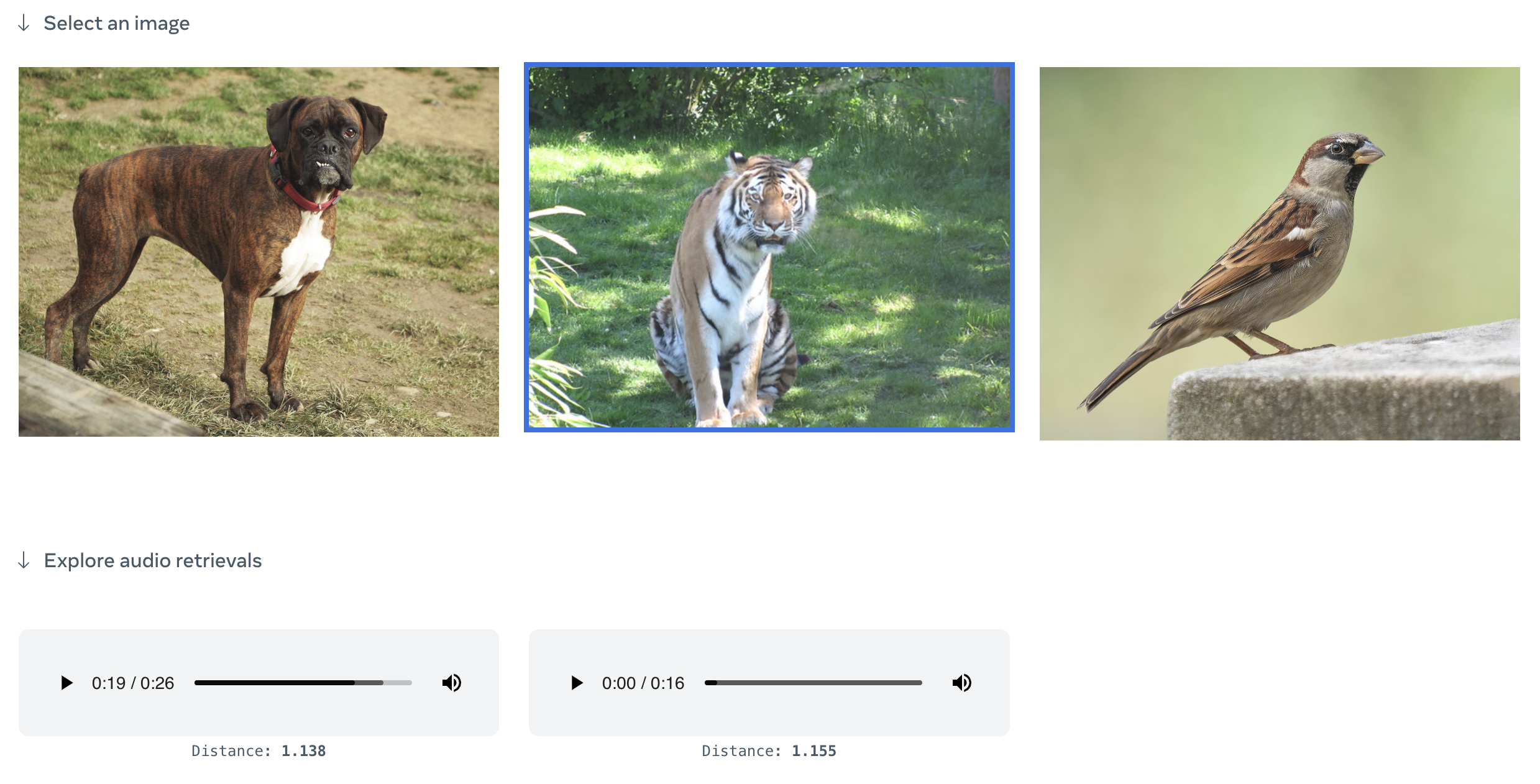
ImageBind is an experimental open-source model from Meta, which was detailed in their May research paper “ImageBind: One Embedding Space To Bind Them All”. ImageBind’s distinguishing feature is the ability to bind information across six modalities: images and video, text, audio, depth (3D), thermal (infrared radiation), and motion (inertial measurement units). This feature creates the ability to retrieve or generate audio from image prompts and generate images from audio, either by itself or in combination with other prompts (image). Meta demonstrated audio-to-image generation by using their own audio embeddings with a pretrained DALL-E decoder and CLIP text embeddings, but the model could theoretically be used with other generative AI tools.
IP Considerations
DALL-E, Midjourney, Stable Diffusion, and Imagen all grant commercial rights for generated images (excluding the free version of Midjourney), but those rights come with limitations unique to AI art.
On March 16th, 2023, the US Copyright Office released guidance stating that AI-generated art cannot be copyrighted because it is not human authored. To qualify for copyright, AI art must be materially modified by human artists.
There are also a number of lawsuits filed against generative AI companies claiming that AI models were unlawfully trained on copyrighted works. Although no legal precedent has been established, the most cautious studios should consider training their own AI models or using products like Adobe Firefly, an art generator that was trained entirely on images that Adobe has the rights to use.